

AI Training Dataset Market Research | Comprehensive Market Analysis and Trends
AI Training Dataset 2024
Artificial Intelligence (AI) and machine learning have revolutionized numerous industries by enabling computers to learn from data and make predictions or decisions without explicit programming. At the core of this transformative technology lies the concept of AI training datasets. These datasets are crucial for training machine learning models, as they provide the necessary data for algorithms to learn patterns, make accurate predictions, and improve over time.
An AI training dataset consists of a collection of data points used to train a machine learning model. This data can be anything from images, text, and audio to more complex datasets like sensor data or transactional records. The quality, quantity, and relevance of this data directly impact the performance of the AI model. High-quality training datasets enable models to make accurate predictions and perform tasks effectively, whereas poor-quality data can lead to inaccurate results and unreliable models.
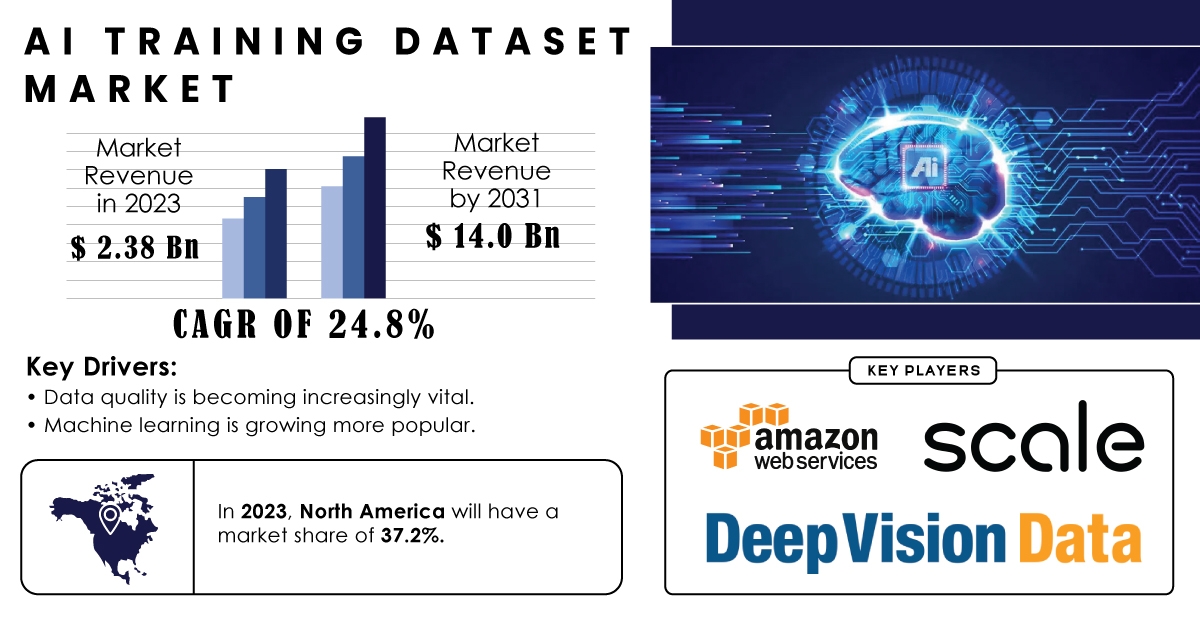
AI Training Dataset Market Size was valued at USD 2.38 billion in 2023 and is expected to increase to USD 14.0 billion by 2031, expanding at a CAGR of 24.8% between 2024 and 2031.
Key Components of AI Training Datasets
-
Data Collection: The process of gathering data from various sources. This can include web scraping, data acquisition from sensors, or purchasing datasets from data providers. The data must be relevant to the problem the AI model is designed to solve.
-
Data Cleaning and Preprocessing: Raw data often contains errors, missing values, or inconsistencies. Cleaning and preprocessing involve removing these issues to ensure the data is in a suitable format for training. This step may include normalization, standardization, and handling missing values.
-
Data Labeling: For supervised learning, data labeling involves annotating data with the correct output or category. For example, labeling images of cats and dogs to train a model to classify animals. This process is crucial for teaching the AI model to recognize patterns and make accurate predictions.
-
Data Augmentation: Enhancing the dataset by creating variations of the existing data. This can include rotating images, changing text formats, or adding noise. Data augmentation helps improve the model's ability to generalize from the training data to unseen data.
-
Data Splitting: Dividing the dataset into training, validation, and test sets. The training set is used to train the model, the validation set to tune hyperparameters, and the test set to evaluate the model's performance. Proper data splitting ensures that the model is evaluated on data it has not seen before, providing a more accurate measure of its performance.
Challenges in AI Training Datasets
-
Data Privacy and Security: Collecting and using data must comply with regulations such as GDPR or CCPA. Ensuring that sensitive data is protected and anonymized is essential to avoid legal and ethical issues.
-
Bias and Fairness: AI models can inherit biases present in the training data. Ensuring diversity and fairness in datasets is crucial to prevent models from making biased or discriminatory decisions.
-
Data Quality: High-quality data is essential for training effective models. Inaccurate or noisy data can lead to poor model performance. Continuous monitoring and updating of datasets are necessary to maintain data quality.
-
Scalability: As AI applications become more complex, the need for larger and more diverse datasets increases. Managing and processing large volumes of data can be challenging and requires robust infrastructure and tools.
Future Trends in AI Training Datasets
-
Synthetic Data Generation: The use of synthetic data, created through simulations or generative models, is on the rise. Synthetic data can supplement real-world data, especially in cases where data is scarce or difficult to obtain.
-
Federated Learning: Federated learning enables models to be trained on decentralized data sources without transferring the data to a central server. This approach enhances data privacy and security while still allowing for effective model training.
-
Automated Data Annotation: Advances in AI and machine learning are making it possible to automate the data labeling process. Automated annotation tools can speed up the process and reduce the need for manual labeling.
-
Enhanced Data Privacy Techniques: Techniques such as differential privacy and homomorphic encryption are being developed to ensure that data used for training AI models remains confidential and secure.
Conclusion
AI training datasets are the backbone of machine learning, providing the data necessary for models to learn and make predictions. The quality and management of these datasets significantly impact the performance of AI systems. As the AI landscape continues to evolve, advancements in synthetic data generation, federated learning, and automated annotation will shape the future of AI training datasets. Addressing challenges related to data privacy, bias, and scalability will be crucial for ensuring the continued success and ethical use of AI technologies.
Contact Us:
Akash Anand – Head of Business Development & Strategy
info@snsinsider.com
Phone: +1-415-230-0044 (US) | +91-7798602273 (IND)
About Us
SNS Insider is one of the leading market research and consulting agencies that dominates the market research industry globally. Our company's aim is to give clients the knowledge they require in order to function in changing circumstances. In order to give you current, accurate market data, consumer insights, and opinions so that you can make decisions with confidence, we employ a variety of techniques, including surveys, video talks, and focus groups around the world.
Read Our Other Reports:
QR Code Payments Market Report