


Introduction
Here, we will observe how to extract Houzz products images data with Python & a BeautifulSoup easily. The purpose of this blog is to start on solve the real-world problems while keeping it easy to help you to become comfortable and also get practical results immediately.
So, the initial entity we wish is to make sure that you have Python 3 installed. So, first of all, install Python 3.
Then, install BeautifulSoup with:
pip3 install beautifulsoup4
We will require LXML, library request, and soupsieve to scrape data, break it into XML, and also utilize the CSS selectors. After that, install them with...
pip3 install requests soupsieve lxml
Once it is installed, open an editor and type:
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup import requests
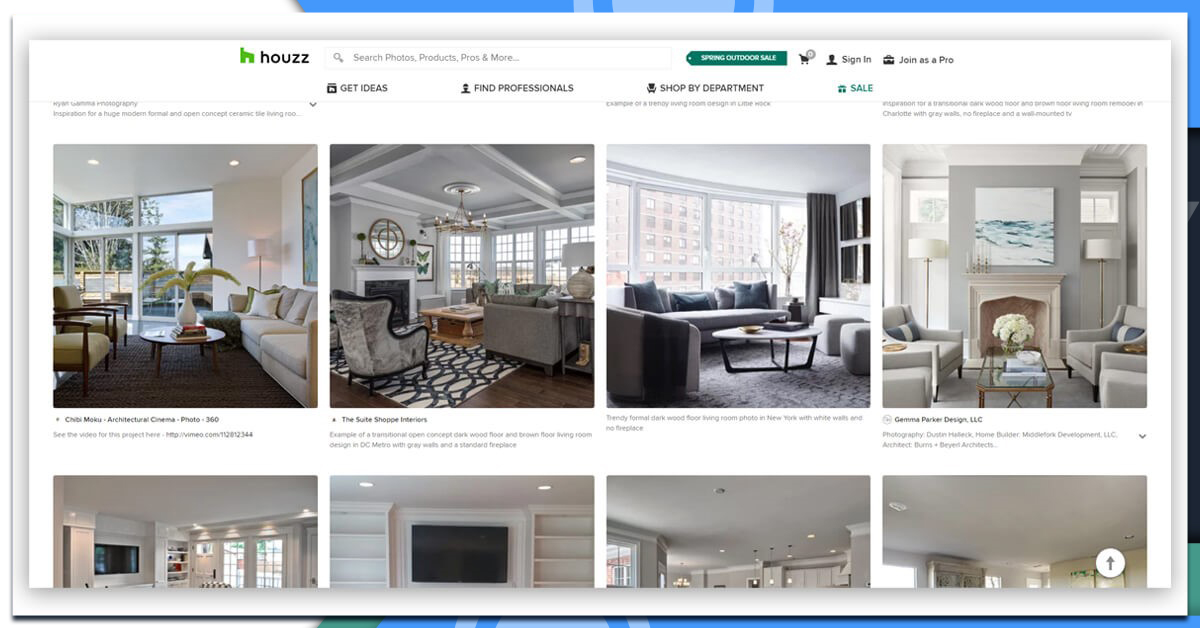
After that, let's visit a Houzz list page and analyze data, which we can scrape.
It will look like this:
Let’s think about the code and try and get data by fantasizing that we are having a browser including that:
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url = 'https://www.houzz.in/photos/kitchen-design-ideas-phbr0-bp~t_26043'
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.content,'lxml')
After that, save this with the name scrapeHouzz.py.
Whenever, you run it:
python3 scrapeHouzz.py
You will observe the whole HTML page.
After that, let's make use of CSS selectors to get the necessary data. To do that, let's utilize Chrome and open the inspect tool.
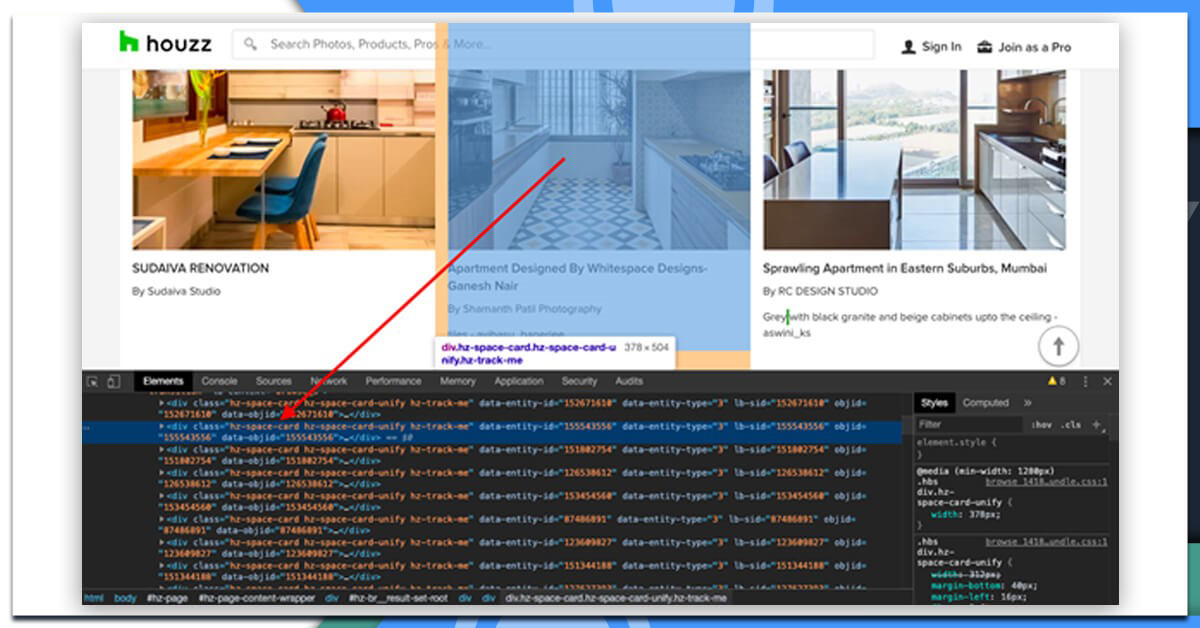
Now, we have observed that all the individual product data are restricted in a div having class 'hz-space-card'. So, we can extract it using CSS selector '.hz-space-card' easily and that’s how its code would look like:
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url = 'https://www.houzz.in/photos/kitchen-design-ideas-phbr0-bp~t_26043'
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.content,'lxml')
for item in soup.select('.hz-space-card'):
try:
print('----------------------------------------')
print(item)
except Exception as e:
#raise e
b=0
This prints content in different containers that grasp the product data.
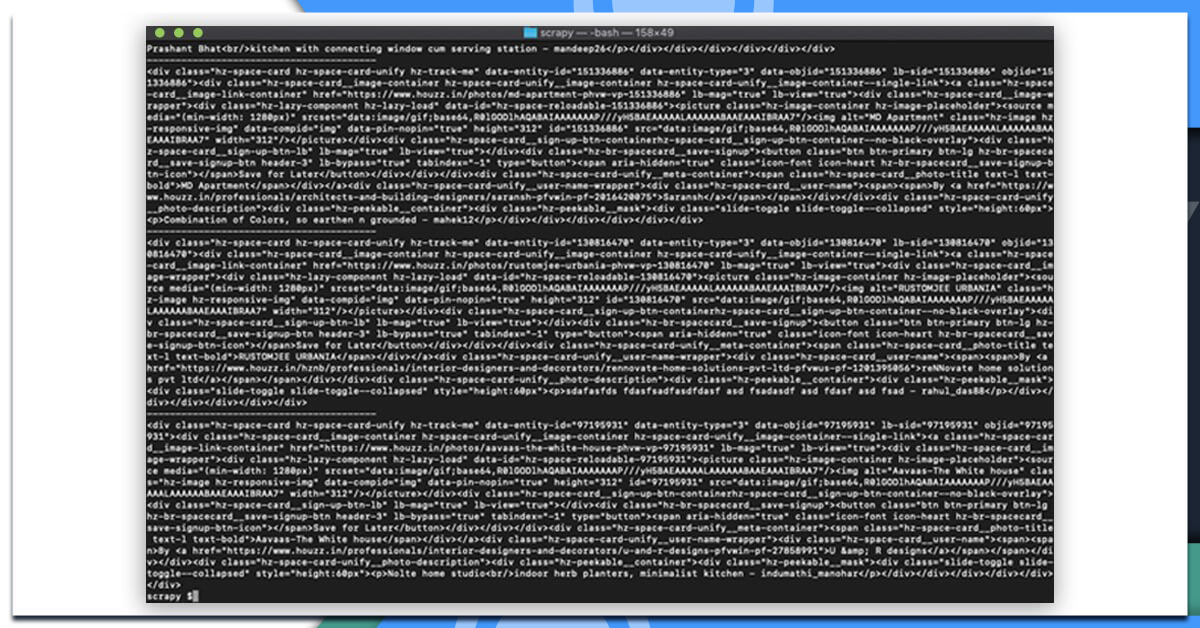
After that, let’s choose classes within the rows that has the required data. We have observed that the title is inside this class hz-space-card__photo-title, the image in hz-image, and more. Therefore, now it looks like that when we will try and get Titles, user names, images, and links for that.
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url = 'https://www.houzz.in/photos/kitchen-design-ideas-phbr0-bp~t_26043'
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.content,'lxml')
for item in soup.select('.hz-space-card'):
try:
print('----------------------------------------')
#print(item)
print(item.select('.hz-space-card__photo-title')[0].get_text().strip())
print(item.select('.hz-image')[0]['src'])
print(item.select('.hz-space-card__user-name')[0].get_text().strip())
print(item.select('.hz-space-card-unify__photo-description')[0].get_text().strip())
print(item.select('.hz-space-card__image-link-container')[0]['href'])
except Exception as e:
#raise e
b=0
Remember, if you run it, it will print all the data:
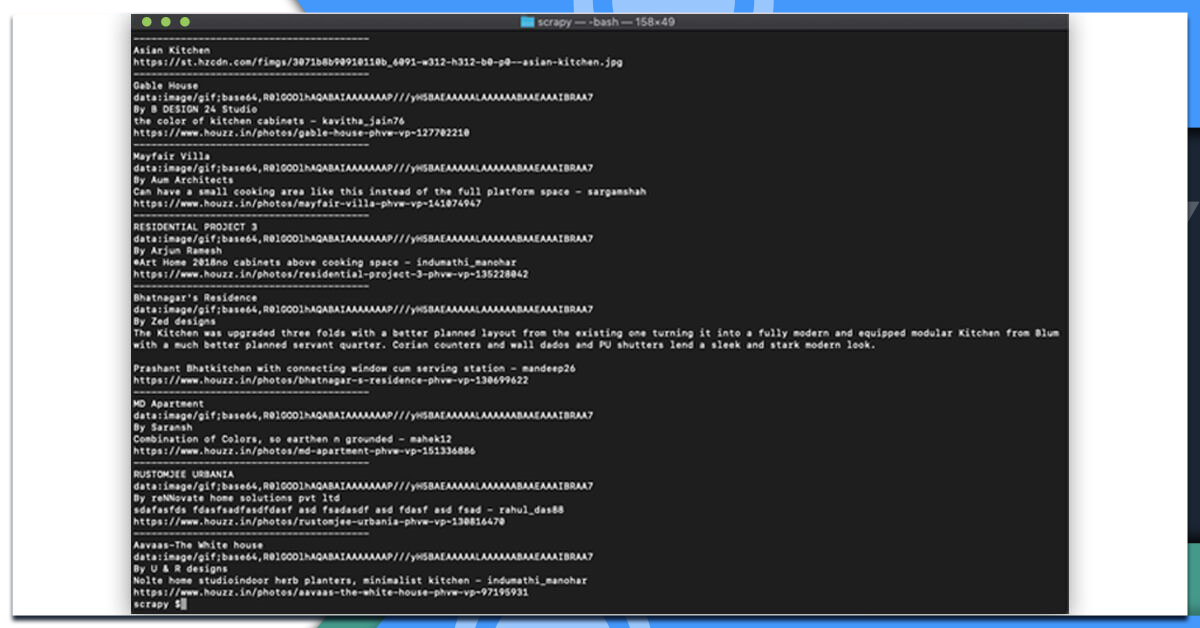
Bingo!! We have received all the data!
If you need to use that in production and want to determine thousands of given links, then you will find out that you can easily have your IP blocked because of this by Houzz. In this situation, using the changing proxy services of rotating IPs is required. You can use services including Proxies APIs for routing calls with any grouping of millions of house proxies.
If you need to increase crawling speed and also don’t want to make any private infrastructure, then you can use our cloud-based scraper to easily extract thousands of URLs at more speed from the crawler networks.